
2025年3月10日至3月14日,第18届国际互联网搜索与数据挖掘大会(The 18th International Conference on Web Search and Data Mining, WSDM 2025)在德国汉诺威召开。浙江大学计算机科学与技术学院ZLST实验室团队的论文“How Do Recommendation Models Amplify Popularity Bias? An Analysis from the Spectral Perspective” 在本次会议录用的106篇论文中脱颖而出,荣获大会唯一最佳论文奖(Best Paper Award)。该奖项为大会唯一最高荣誉,也是继清华大学2022年后中国高校再次获此殊荣。

(获奖证书)

(会议颁奖现场)

(第一作者林思仪在会议现场进行学术报告)
会议介绍

国际互联网搜索与数据挖掘大会(WSDM)由国际计算机学会(ACM)所属信息检索(SIGIR)、数据挖掘(SIGKDD)、数据库(SIGMOD)、网络信息处理(SIGWEB)四个专委会共同举办,在相关领域享有很高学术声誉,每年吸引全球学术界和工业界的顶尖研究者参与。WSDM也入选计算机学会B类、清华大学A类学术会议。2025年WSDM会议于德国汉诺威召开,以17.3%的录用率共接收论文106 余篇,其中仅 1 篇获评最佳论文。往年最佳论文奖获奖单位包括康奈尔大学、卡内基梅隆大学、清华大学、牛津大学等世界一流大学和微软、谷歌等知名企业。
论文介绍
推荐系统中的流行度偏差是指推荐模型在长尾数据上进行优化时,会继承和放大这种长尾效应,导致推荐出来的结果会更加偏向于流行的物品,从而造成信息茧房、马太效应等问题。这篇工作首次从理论角度解释了推荐系统中流行度偏差的成因,为偏差分析和长尾优化带来新的视角(频域角度),并基于这个理论框架提出了一种简单而有效的新纠偏方法,相比于现有方法带来显著的性能提升。该技术在推荐系统、图挖掘、内容检索等长尾数据场景均展现出良好的应用潜力。
具体而言,这篇工作通过理论和经验分析解释了推荐模型记忆和放大流行度偏差的内在机理:1)物品流行度信息会被记忆在模型预测矩阵的主频谱里;2)由于推荐模型内在的维度衰减问题,主频谱的作用会被放大因此导致流行度在预测中起着更大的作用。
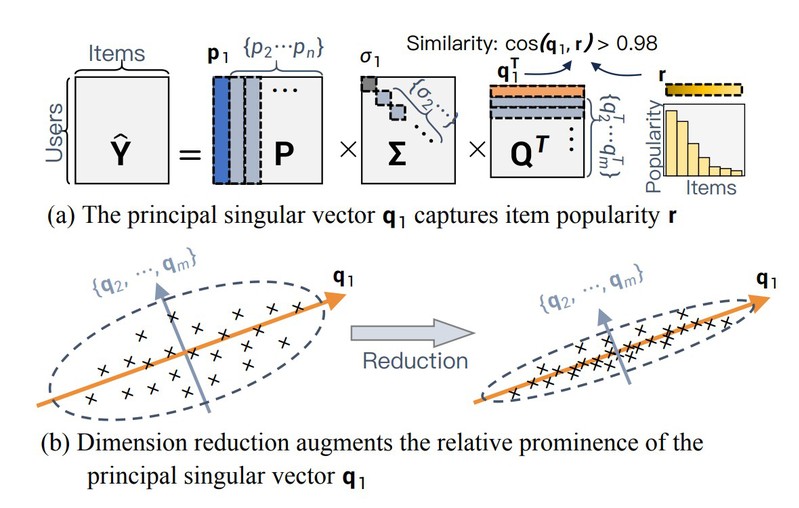
(图:推荐模型记忆和放大流行度偏差的内在原因示意图)
基于以上分析,该论文针对性地从谱角度提出了一个简单有效的基于谱范数约束的纠偏方法,并在七个真实数据集和三种测试模式下表现出最佳性能。
论文原文:https://arxiv.org/pdf/2404.12008
详细中文介绍:https://mp.weixin.qq.com/s/D9xS_1c3ClMtqO2x62O5yQ
实验室团队介绍
浙江大学计算机学院ZLST实验室由陈纯院士领衔,长期从事大数据智能研究工作,特别是近年来在大语言模型、扩散模型、可信推荐系统、模型压缩等前沿领域产出了丰硕的学术成果,团队曾获省部级奖科技奖项5项,国际顶级学术会议最佳论文相关奖项5项。ZLST Lab欢迎优秀老师、同学的加入,期待在大模型时代为人工智能领域搬砖添瓦!
实验室主页:https://zlstwebsite.github.io/Zlst/home/

